有哪些日常实用的 AI 工具、AI 插件、AI 软件或应用推荐?

那应该是我的AI工具箱了,开始写的时候专注AI作画,后来功能越加越多,目前功能:
- AI作画:Disco Diffusion、Stable Diffusion、Control net1.1、T2iadapter
- 图片高清修复、老照片修复
- 图片转3D
- AI写小说、训练小说、chatgpt清华版本chatglm
- GAN类二次元、三次元生成
- 黑白图片、视频上色
- 图片视频、音频驱动说话人
- AI生成描述、AI解析图片描述
- 伴奏人声分离
- 一键抠图
- 视频补帧
- 音频、视频转文字或者字幕
如下针对一些功能做一些介绍吧:
01 软件概览
软件名字叫做:AI作画离线版V5.0(基于Disco Diffusion 5.6与Stable Diffusion),基于GitHub上的开源项目Disco Diffusion与Stable Diffusion。
如下,软件主界面,还是以操作简单为主:
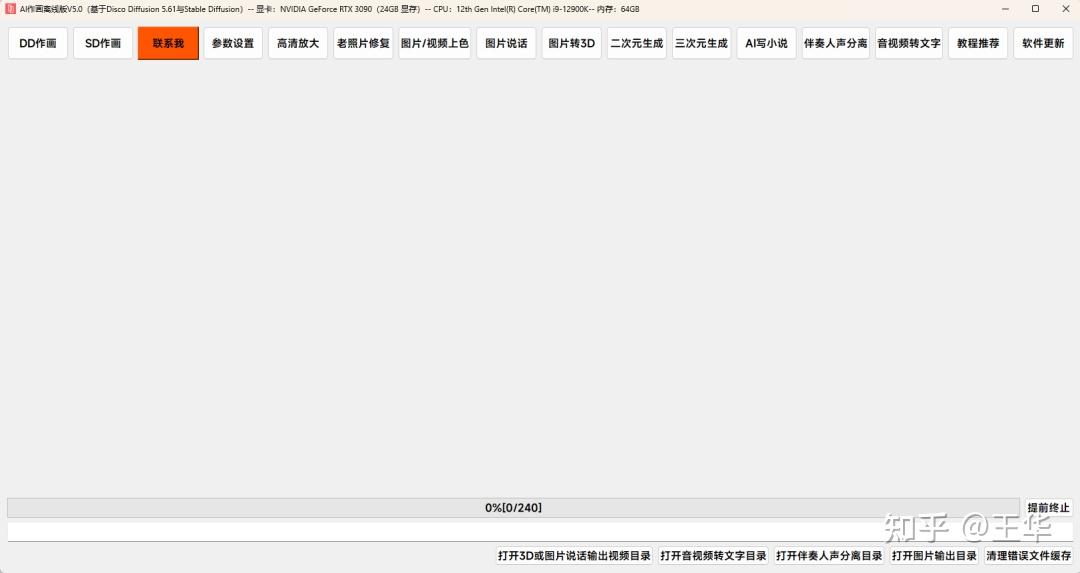

02 软件安装
软件非常大,因为有很多离线模型,下载完成后,按照网盘里的pdf教程即可进行体验。
软件界面如下所示:


03 软件功能介绍
功能一:DD(Disco Diffusion)作画
软件目录文件夹的settings.json就是作图配置文件,当然离线版本可通过界面进行设置了。
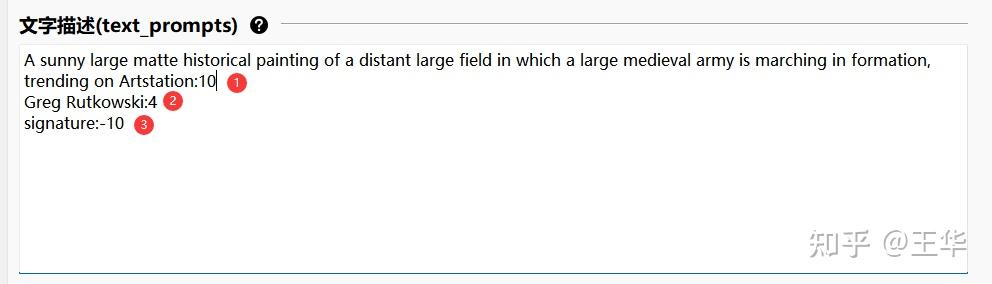
1、描述词设定:描述词之前手动修改json文件经常有小伙伴少输入标点导致出错,界面化可以避免这个问题,如下默认的描述,每段(回车换行算一段)都是同一描述的不同权重关键词。

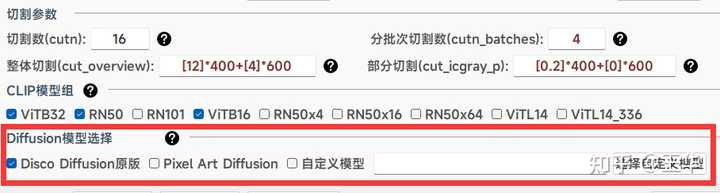
2、AI作画模型选择:参数设置里提供两种绘图Diffusion模型引擎选择,原版DD、像素版DD以及其他自定义的PT格式模型,如下图设置:

像素模式作画引擎也可以试试,如下就是像素风格的图,也挺有意思:




自定义模型比如选择国画风或者人像的PT模型文件,然后保存设置即可。


如下演示的是国画模型和人像1.5模型的测试样图:




AI图片描述解析:如下按钮点击,选择图片,稍等片刻即可显示出描述,当然这个描述有所出入,但当作描述来用画出的图也确实不错。
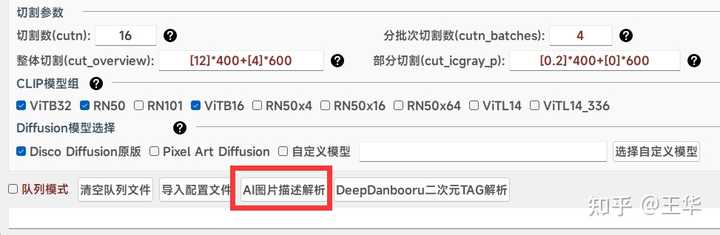

下面演示几张图,解析出来的描述:
a couple of people riding bikes down a road, a matte painting by Makoto Shinkai, featured on pixiv, rayonism, official art, anamorphic lens flare, matte painting


a group of iron man standing next to each other in the ocean, a comic book panel by Paul Pelletier, featured on deviantart, antipodeans, marvel comics, reimagined by industrial light and magic, imax


a painting of a landscape with mountains and trees, a detailed matte painting by Katsukawa Shunsen, pixiv, shin hanga, ukiyo-e, matte painting, detailed painting


功能二:SD(Stable Diffusion)作画
SD作画功能和DD功能基本一致,同样支持队列模式、参考图等功能,SD作画速度更快,且画得更加具象,下面主要介绍SD的参数设置。
同样SD也是具有文字描述和参考图功能,还有一些其他参数,大家可以鼠标悬停到参数旁边的问号就会有说明。
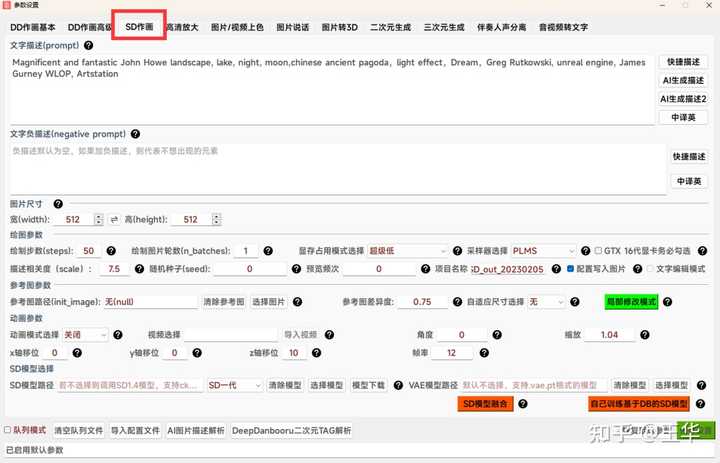

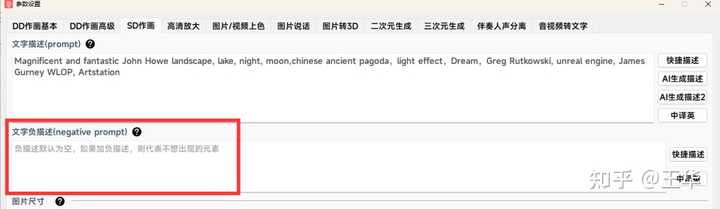
1、描述词设定:描述词句式基本和DD一样,但SD作画多了个负描述,负描述默认可以不写,负描述如果写,就代表不想让绘画结果出现的元素。

支持写个开头,然后如下点击AI生成描述进行续写描述,目前有两种自动写描述引擎了:


2、绘图参数:图片尺寸和DD一样,需要64的倍数,当然随便填写尺寸也行,软件会自动转换;绘图步数和DD类似,不过SD步数50就够了,多了没啥意义;绘制图片轮数代表每次画几张图;描述相关度默认数值就可以,当然可以尝试10以上数值;随机种子默认0,代表每次种子随机,设置大于零的固定值,如果其他参数一样,则SD出图完全一样,这点和DD不一样哈。


3、参考图:和DD一样,SD也支持参考图,不过参数比较简单,基本上就是导入原图,修改描述,设置图片差异度参数即可,注意差异度参数范围0-1,1代表与参考图差异最大哈。另外,自适应尺寸比较人性化,比如参考图尺寸宽高为1024x512,绘图参数尺寸设置512×512,默认无,代表不自适应,最终出的图尺寸为512×512,固定宽代表,以绘图参数尺寸设置的宽512为准,参考图宽高比2比1,高自动修改为256,最终输出512x256的图。


如下,试试SD参考图,实现真人参考图用二次元描述实现真人二次元效果:












4、自定义SD模型选择:支持选择第三方ckpt、safetensors格式的SD模型以及VAE模型,如下所示,选择模型所在路径即可实现利用第三方SD模型作画。注意的是导入的模型要区分是SD一代还是二代,在下拉列表里自行选择,否则报错。


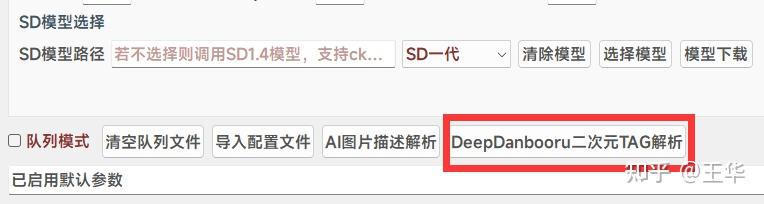
5、DeepDanbooru二次元TAG解析:如下点击按钮,支持二次元图片的TAG解析,诸如NovelAI等模型比较有需求:

功能三:图片AI高清放大
设置不同的放大模型和图片放大倍数,高清放大图片输出目录为软件目录\images_out\AI_ultra_HD,当输入的图片尺寸很大时,容易超显存,这时我们修改拼图大小这个参数即可,比如设置拼图大小512时,6G显存选择realesrgan_x4plus模型对1920*1080图片进行4倍放大测试不超显存。支持2-10倍放大。


AI高清放大是一个独立功能,如下软件主界面点击高清放大按钮,选择图片(支持批量),即可高清放大图片。

如下,小图经过高清放大的对比效果,二次元和三次元都能胜任。





功能四:老照片修复
如下软件主界面点击老照片修复按钮,选择图片(支持批量),即可高清修复老照片,仅对人像进行高清修复。


如下,经过高清人脸修复对比效果动图演示:





功能五:图片/视频上色
如下软件主界面点击图片/视频上色按钮,即可实现对黑白照片或者视频上色:


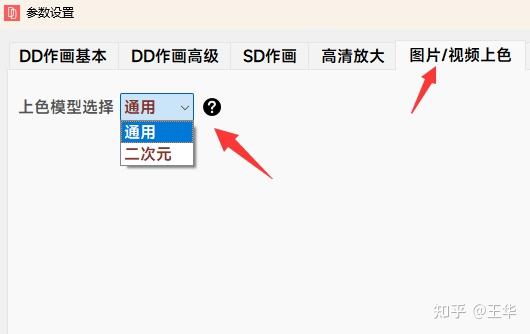
如下参数设置里,可以选择不同上色模型,二次元模型专注二次元线稿上色:

如下动图演示,上色前后的效果:



功能六:图片说话
图片说话功能,可以实现导入的方图转换成说话人视频的形式,支持自己录制说话视频,注意无论是图片和参考视频,需要方形和人脸居中的视频。

然后,如下软件主界面点击图片说话,选择图片(支持批量),转换图片成如下的视频形式。




功能七:AI图片转3D
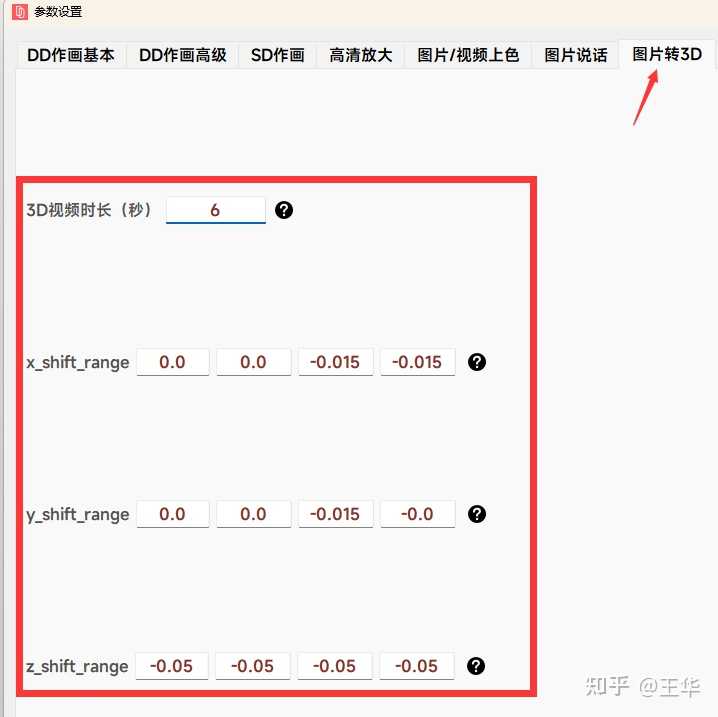
AI图片转3D输出视频目录:软件目录\video;AI图片转3D也是一个独立免费功能,如下参数设置可以设置生成视频时长和摄像头位置(位置一般不改):

然后,如下软件主界面点击图片转3D,选择图片(支持批量),转换图片成如下的视频形式,这个转换速度较慢,5到30分钟一张图。

基本上就是原作项目介绍的这种效果,一张精图转换成3D的效果,不过相比原作我做了改进,支持原图尺寸大小的视频。

功能八:二次元生成
如下点击二次元小姐姐生成按钮,即可绘制上百张二次元图片:


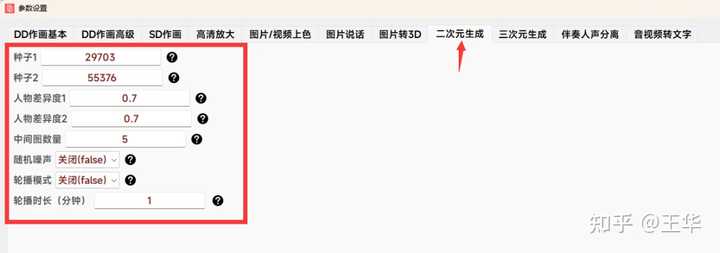
如下可在参数设置里,设置各种参数以生成不同类型的二次元小姐姐:

功能九:三次元生成
和二次元生成功能一样,如下点击三次元生成按钮,即可绘制多张三次元全身图:


如下可在参数设置里,设置各种参数以生成不同类型的三次元图片:


功能十:AI写小说
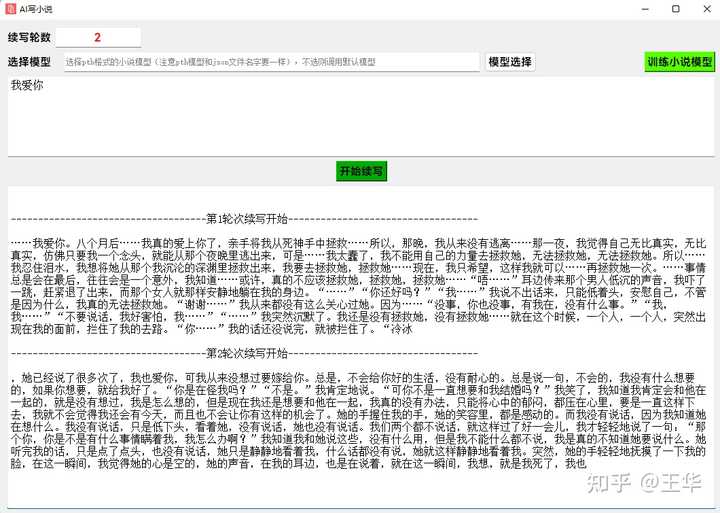
如下点击AI写小说按钮,设置开头,即可续写不同轮数的文字:


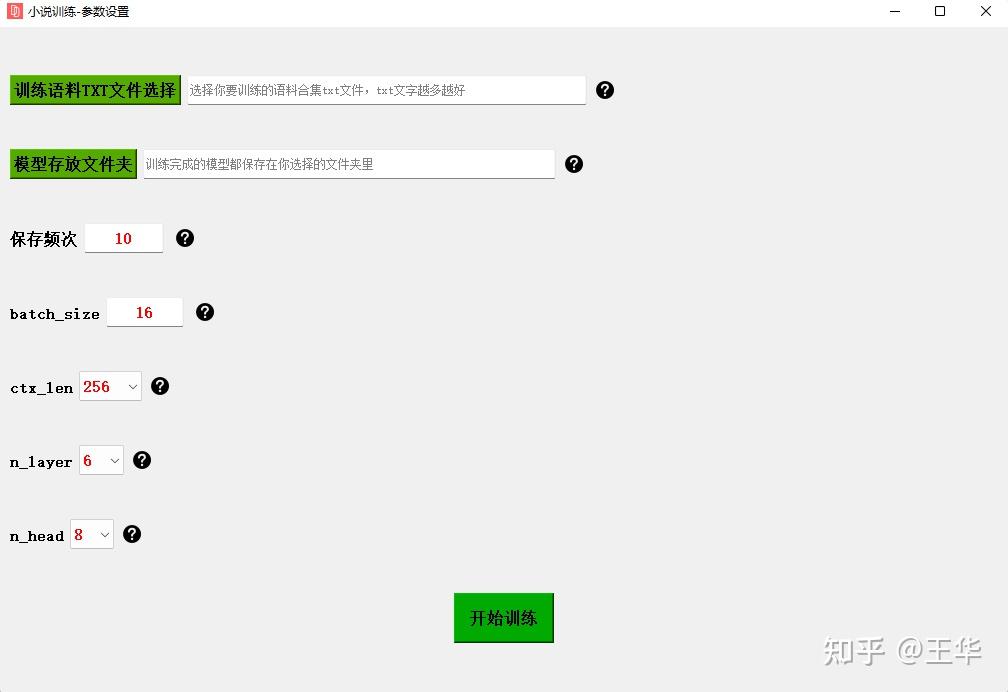
点击训练小说,如下可以选择自己的小说语料txt,训练自己的模型:

功能十一:伴奏人声分离
如下点击伴奏人声分离按钮,选择歌曲(支持批量),即可自动分离人声、伴奏、鼓点和低音,效果很厉害。

若显存4G及以下,可以如下参数设置勾选低显存占用模式即可:


功能十二:音视频转文字
如下点击音视频转文字按钮,选择音频或者视频,即可进行语音识别,输出字幕和文字版txt文件。

音视频转文字功能,支持100多个国家语言,若选择汉语,则不过什么语言的音视频,最终都会自动翻译成中文字幕和txt文件,方便快捷,不过翻译效果有限,最好还是选择原视频语言进行识别。


如下,选取的日文视频演讲识别字幕效果,红框为软件识别自动翻译的字幕:


04 显卡要求
需要至少2GB显存,且必须是英伟达显卡,AMD、intel等不支持。
各种显存测试参数可参考:https://docs.qq.com/sheet/DTGxSSkNJcnVhV1VP。
05 小结
这个项目确实很有意思,唯一的问题就是对显卡要求高,最起码需要英伟达2G及以上显存,AMD等其他显卡不支持,感兴趣的可以体验一下5.0版本了,更详细的作图参数、教程多刷刷B站相关视频即可。
06 本期内容获取
方式一:百度网盘 https://pan.baidu.com/s/1B0g4MPFe_drP_hRjgEnKGg 提取码:95kh
方式二:天翼网盘
https://cloud.189.cn/t/ZZ7vuyZrMvmm (访问码:7dn8)