亚马逊AWS官方博客
从 AWS Lambda 访问适用于 Redis 的 Amazon MemoryDB
今天是适用于 Redis 的 Amazon MemoryDB 推出一周年纪念日。2021 年 8 月 19 日,AWS 宣布正式推出适用于 Redis 的 Amazon MemoryDB,这是一款与 Redis 兼容的完全托管式数据库,可提供内存中性能和多可用区耐用性。
在过去的一年里,成千上万的客户已将 MemoryDB 作为他们的主要数据库,来处理需要极高性能的关键工作负载。金融科技、智能家居和互联网服务等行业的客户都在使用 MemoryDB 作为超快的主数据库,为用户会话数据、金融代币、微服务之间的消息流、游戏状态和排行榜以及物联网等使用案例提供支持。自推出该服务以来,我们已经提供了许多功能,包括 2 个月免费试用、本机 JSON(JavaScript 对象表示法)支持、AWS Controllers for Kubernetes(ACK)for Amazon MemoryDB 的开发者预览版以及 Redis 6.2.6 支持。媒体热议的是,我们最近宣布 MemoryDB 符合 PCI DSS 和 HIPAA 要求。
MemoryDB 专为云原生应用程序而构建,使用内存中存储和多可用区事务日志提供超快的性能,以实现数据持久性。在这篇博文中,我想分享一个示例,说明客户如何使用 MemoryDB 在其运行于 AWS Lambda 上的无服务器应用程序中提供超快的共享状态。
解决方案概览
Lambda 是一种让您在运行代码时无需预置或管理服务器的无服务器事件驱动型计算服务。Lambda 在高可用性计算基础设施上运行您的代码,并执行计算资源的所有管理,包括服务器和操作系统维护、容量预置和自动扩展、代码监控和日志记录。借助 Lambda,您几乎可以为任何类型的应用程序或后端服务运行代码。您所需要做的就是使用 Lambda 支持的语言之一提供您的代码。
Lambda 函数通常需要数据库来跨调用存储数据(如用户会话或函数状态)。MemoryDB 是专为需要超快性能的应用程序而构建的数据库,是实现 Lambda 函数持久共享状态的绝佳选择。您可以在 VPC 中创建 MemoryDB 端点。Lambda 函数始终在 Lambda 拥有的 VPC 中运行。Lambda 将网络访问和安全规则应用于此 VPC,并自动维护和监控 VPC。要启用对 MemoryDB 集群的访问,您需要配置 Lambda 函数的 VPC 和安全设置。
在这篇博文中,我将解释如何使用 Redis 客户端设置 Lambda 函数来访问 MemoryDB,以及如何配置 Lambda 函数来访问您的 MemoryDB 数据库。
创建 MemoryDB 数据库
首先,通过几个简单的步骤创建一个新的 MemoryDB 数据库。请完成以下步骤:
- 在 MemoryDB 控制台的导航窗格中选择 Clusters(集群)。
- 选择 Create cluster(创建集群)。
- 对于 Name(名称),输入集群的名称。

- 对于 Subnet groups(子网组),选择 Choose existing subnet group(选择现有子网组),然后为您的 MemoryDB 数据库选择一个子网组。您选择的子网组指定了可从哪个 VPC 访问您的 MemoryDB 集群。它还决定了放置 MemoryDB 实例的可用区。在本例中,我使用了之前创建的子网组,该子网组包含三个可用区,VPC ID 为
vpc-9a4237e7。记下此 VPC ID。在后面的步骤中,您将在同一 VPC 中创建 Lambda 函数。
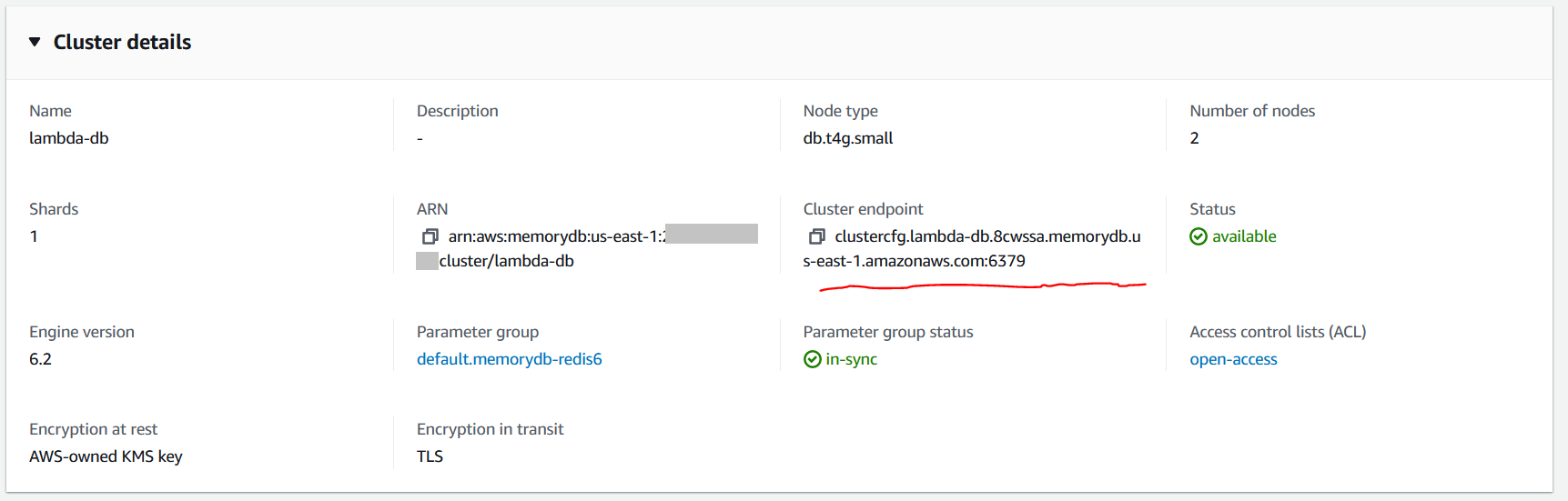
- 在 Cluster settings(集群设置)部分中,选择集群设置,包括节点类型、分片数量和每个分片的副本数量。在本例中,我使用的是 db.t4g.small 节点类型,因为它的大小适合测试数据库。对于生产工作负载,建议您根据预期的数据库大小选择正确的节点类型。只读副本可帮助您扩展读取吞吐量,而不会使分片中的主节点负担过重。您应该根据读取吞吐量选择正确的副本数量。在此处详细了解如何为集群选择正确的节点和副本数量。对于本测试,我选择了一个分片,每个分片有一个副本。
- 单击 Next(下一步)。

- 在 Inbound rules(入站规则)下,选择您的安全设置。
- 如果您还没有安全组,请新建一个安全组。默认情况下,客户端使用端口 6379 上的 TCP 协议连接到 MemoryDB。确保您的安全组允许客户端通过此端口进行连接。您可以使用以下屏幕截图所示的设置添加新的入站规则,从而启用此功能。这允许同一安全组中的任何客户端使用 TCP 连接到端口 6379。
- 选择 Save rules(保存规则)。

- 在 Advanced settings(高级设置)部分中,选择您的安全组并指定其加密设置。

- 选择维护时段和备份的设置,然后选择 Create cluster(创建集群)。这将在几分钟内创建一个新的 MemoryDB 数据库。
- 创建 MemoryDB 数据库后,请记下集群设置中的集群端点。您将在下一步配置此端点。
使用 Redis 客户端创建节点项目
在此步骤中,您将使用 ioredis(Node.js 的 Redis 客户端)创建新的节点项目。我将演练安装 Node.js、Redis 客户端和连接到 MemoryDB 的示例代码的所有步骤。
- 通过在命令行输入以下内容来安装节点版本管理器(nvm):
- 激活 nvm:
- 使用 nvm 安装最新版 Node.js:
- 测试 Node.js 是否已安装并正常运行:
这将显示以下消息,其中显示正在运行的 Node.js 版本:
- 安装最新的节点包管理器(npm):
- 为您的项目创建一个新文件夹,然后在文件夹中创建一个节点项目:
- 安装 Redis 客户端:
- 现在,您可以创建
index.js文件。替换以下代码中的 MemoryDB 端点 URL:此示例代码连接到您的 MemoryDB 集群,并设置新键值对
foo和bar。该代码还会返回键foo的值,作为要由 Lambda 函数打印的响应。 - 打包您的代码(包括 Redis 客户端依赖项),以便将其上传到 Lambda 中。在项目文件夹中,使用以下命令创建一个 .zip 文件:
创建新的 Lambda 函数
在此步骤中,您将创建新的 Lambda 函数。由于 MemoryDB 在 VPC 中运行,因此我们必须配置 Lambda 函数才能访问 VPC 中的资源。
创建执行角色
要为 Lambda 创建 AWS Identity and Access Management 角色,请完成以下步骤:
- 在 IAM 控制台上,在左侧导航窗格中选择 Roles(角色)。
- 选择 Create role(创建角色)。
- 对于 Trusted entity type(可信实体类型),选择 AWS Service(AWS 服务)。
- 对于 Use case(使用案例),选择 Lambda。
- 单击 Next(下一步)。
- 搜索权限策略
AWSLambdaVPCAccessExecutionRole并选择它。 - 单击 Next(下一步)。
- 提供一个角色名称,如
lambda-vpc-role。 - 选择 Create role(创建角色)。
创建新的 Lambda 函数
现在,您可以创建 Lambda 函数了。
- 在 Lambda 控制台的导航窗格中选择 Functions(函数)。
- 选择 Create function(创建函数)。
- 对于 Function name(函数名称),输入函数的名称。

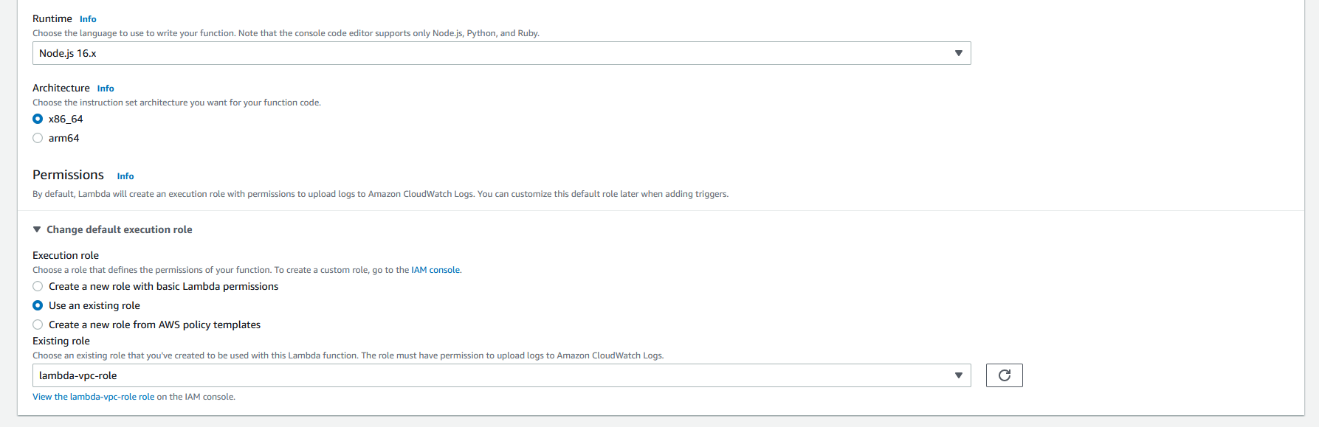
- 对于 Execution role(执行角色),选择 Use an existing role(使用现有角色),然后选择您刚刚创建的角色。
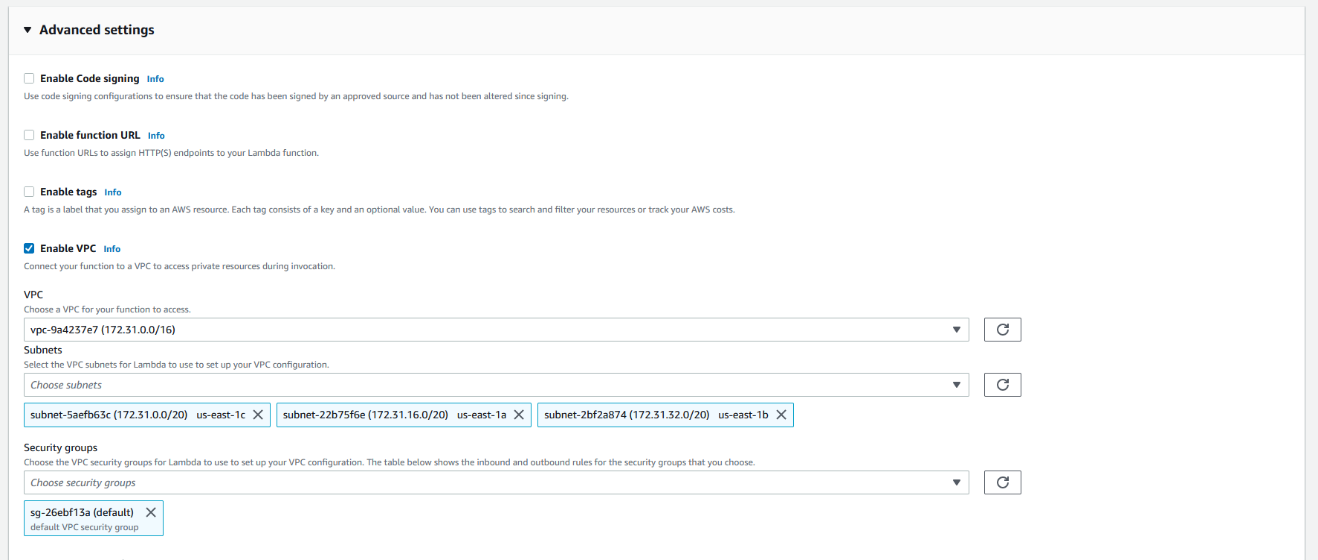
- 展开 Advanced Settings(高级设置)。在这里,您可以将 Lambda 函数连接到 VPC,以便它可以访问您的 MemoryDB 集群。
- 选择 Enable VPC(启用 VPC)。
- 选择您创建的 VPC(您在创建 MemoryDB 集群时选择的同一 VPC)。
- 为您的 Lambda 选择要使用的 VPC 子网。
- 为您的 Lambda 选择安全组(您在创建 MemoryDB 集群时选择的同一安全组)。
- 选择 Create function(创建函数)。
这会为您创建一个空白函数。
部署您的函数
接下来,通过上传之前创建的 .zip 文件,将代码部署到 Lambda 函数。
有两种方法可以做到这一点。如果您将 .zip 文件存储在本地计算机上,则可以直接上传。或者,您也可以将文件上传到 Amazon Simple Storage Service(Amazon S3),然后将其导入 Lambda。

接下来,您就可以测试代码了。在函数的 Test(测试)选项卡上,选择 Test(测试)。

您的 Lambda 函数应成功连接到 MemoryDB。您的代码会将键值对 foo 和 bar 写入 MemoryDB,并返回要作为输出在 Lambda 函数中打印的值。

恭喜! 现在,您的 Lambda 函数可以在您的 MemoryDB 数据库中插入和读取数据了。
清理
看完一个实际示例后,下面我们来整理一下工作。完成以下步骤以清理您的 Lambda 函数和 MemoryDB 数据库:
- 在 Lambda 控制台的导航窗格中选择 Functions(函数)。
- 选择您创建的函数。
- 在 Actions(操作)菜单中,选择 Delete(删除)。
- 在 MemoryDB 控制台的导航窗格中选择 Clusters(集群)。
- 选择您创建的集群。
- 在 Actions(操作)菜单中,选择 Delete(删除)。
结论
在这篇博文中,我展示了如何创建和配置 Lambda 函数来访问 MemoryDB 集群。您的 Lambda 函数现在可以在与 Redis 兼容的数据库中跨函数调用持久存储数据,并提供超快的读写性能。我从 AWS 管理控制台手动设置了 MemoryDB 集群,但您也可以使用 MemoryDB API 以编程方式设置 MemoryDB 集群。您还可以使用 AWS Controller for Kubernetes for MemoryDB 直接从 Kubernetes 集群定义和管理 MemoryDB 资源。
我很期待看到大家将如何使用 MemoryDB 来存储 Lambda 函数的数据。开始使用 MemoryDB 时,您可以免费试用 2 个月。如有任何疑问或功能请求,请发送电子邮件至 memorydb-help@amazon.com。
关于作者
 Abhay Saxena 是 Amazon Web Services 内存数据库团队负责适用于 Redis 的 Amazon MemoryDB 的产品经理。他与 AWS 客户合作,确定客户可能从内存数据库的超快性能中受益的需求。加入 MemoryDB 团队之前,Abhay 在 Amazon 担任产品经理已超过 13 年。
Abhay Saxena 是 Amazon Web Services 内存数据库团队负责适用于 Redis 的 Amazon MemoryDB 的产品经理。他与 AWS 客户合作,确定客户可能从内存数据库的超快性能中受益的需求。加入 MemoryDB 团队之前,Abhay 在 Amazon 担任产品经理已超过 13 年。