亚马逊AWS官方博客
Amazon Redshift 数据共享最佳实践和考虑因素
是一个快速、完全托管式云数据仓库,可简化并使通过标准的 SQL 和您的现有商业智能(BI)工具对您的全部数据进行分析变得更具成本效益。借助 Amazon Redshift 数据共享,您可以安全轻松地在 Amazon Redshift 集群之间共享实时数据以供读取。它让 Amazon Redshift 创建者集群可以与一个或多个 Amazon Redshift 使用者集群共享对象以实现读取目的,而无需复制数据。通过这种方法,隔离到不同集群的工作负载可以经常共享和协作处理数据,从而推动创新,并为内部和外部利益相关者提供增值分析服务。您可以在多个级别(包括数据库、架构、表、视图、列和用户定义的 SQL 函数)共享数据,以提供可为所有需要访问 Amazon Redshift 数据的用户和企业量身定制的精细访问控制。该功能本身易于使用,并可集成到现有的 BI 工具中。
Amazon Redshift 数据共享如何运作?
- 为了实现出色的性能,Amazon Redshift 使用者集群缓存并增量更新从创建者集群中查询的对象的数据块级数据(我们称之为块元数据),即使在集群暂停时也能正常工作。
- 缓存块元数据所花费的时间取决于自使用者上次查询相应对象以来创建者的数据更改的速率。(截至目前,使用者集群仅在需要时更新对象的元数据缓存,即在查询时更新)
- 如果存在频繁的 DDL 操作,使用者会被迫在下次访问期间重新缓存对象的完整块元数据,以保持一致性,因为为了实现实时共享,在创建者上的结构变化会使使用者上现有的元数据缓存失效。
- 使用者将块元数据与创建者上某个对象的最新状态同步后,查询将作为任何其他常规查询(引用本地对象的查询)来执行。
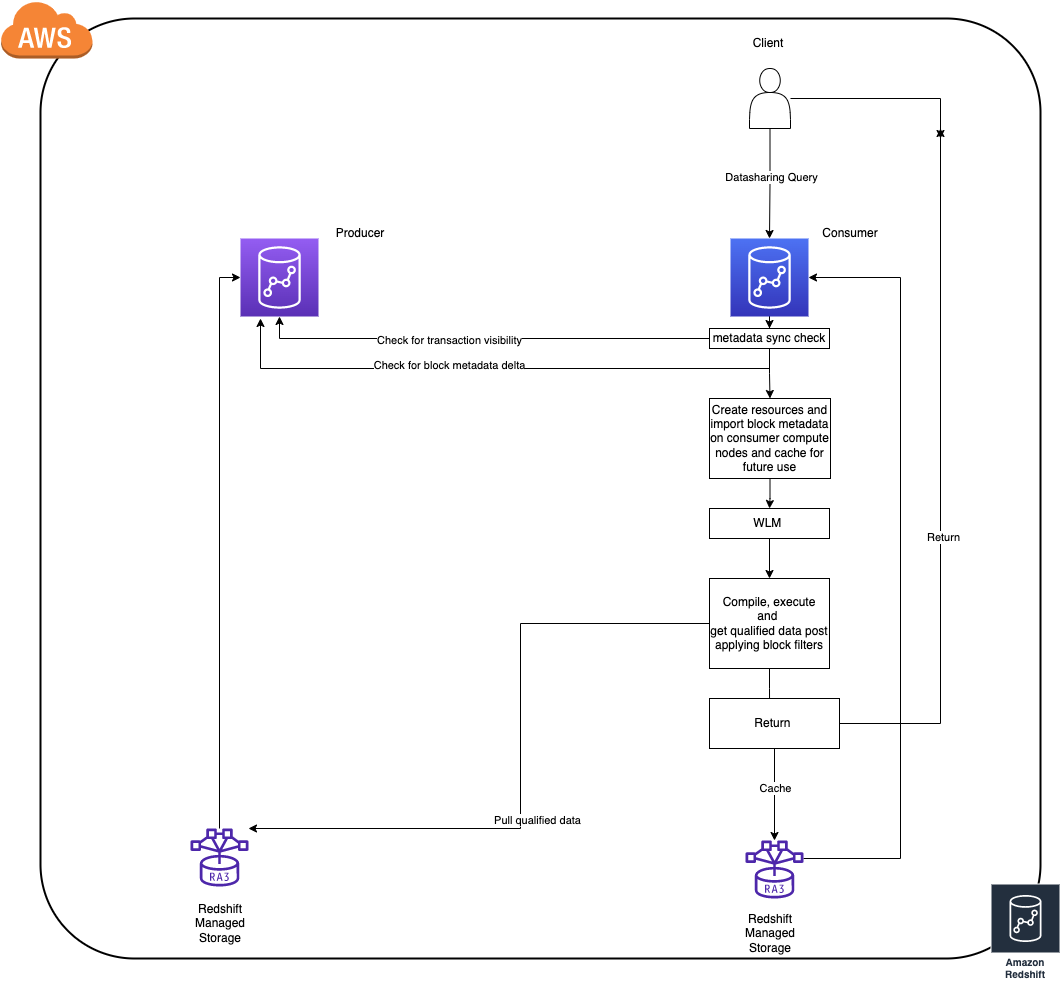
现在,我们已经掌握了数据共享及其工作原理的必要背景知识,接下来我们来看一些可以在使用数据共享时帮助改善工作负载的串流间最佳实践。
安全
在本节中,我们将分享使用 Amazon Redshift 数据共享时的一些最佳安全实践。
谨慎使用“INCLUDE NEW”
在向数据共享(ALTER DATASHARE)添加架构时,INCLUDE NEW是一个非常有用的设置。如果设置为 TRUE,则将来在指定架构中创建的所有对象自动添加到数据共享。在您希望对共享的对象进行精细控制的情况下,这种方法可能并不适宜。在这些情况下,请将该设置保留为默认值 FALSE。
使用视图实现精细的访问控制
要实现对数据共享的精细访问控制,您可以在使用者的共享对象上创建延后绑定视图或实体化视图,然后将这些视图的访问权限共享给使用者集群上的用户,而不是授予对原始共享对象的完全访问权限。这有其自身的一系列考虑因素,我们将在本文稍后部分进行说明。
审核数据共享使用情况和更改
Amazon Redshift 提供了一种有效方法,使用系统视图审核与数据共享有关的所有活动和更改。我们可以使用以下视图来检查这些详细信息:
- SVL_DATASHARE_CHANGE_LOG – 记录使用者集群上数据共享的活动和使用情况
- SVL_DATASHARE_USAGE_CONSUMER – 记录使用者集群上数据共享的活动和使用情况
- SVL_DATASHARE_USAGE_PRODUCER – 记录创建者集群上数据共享的活动和使用情况
性能
在本节中,我们将讨论与性能相关的最佳实践。
数据共享环境中的实体化视图
实体化视图(MV)为需要高吞吐量的使用案例提供了预先计算复杂聚合的强大途径,您也可以通过数据共享直接共享实体化视图对象。
对于基于频繁写入操作的表构建的实体化视图,理想的做法是在创建者自身上创建实体化视图对象并共享视图。这种方法使我们有机会集中管理创建者集群本身的视图。
对于缓慢变化的数据表,可以直接共享表对象,并直接在使用者上构建共享对象的实体化视图。这种方法使我们可以根据您的使用案例灵活地创建每个使用者的自定义数据视图。
这有助于优化数据共享查询生命周期中的块元数据下载和缓存时间。这也有助于实体化视图刷新,因为在撰写本文时,Redshift 不支持基于共享对象构建的 MV 的增量刷新。
使用跨区域数据共享时需要考虑的因素
即使创建者和使用者位于不同的区域,也支持数据共享。在跨区域实施共享时,我们需要考虑一些差异:
- 对于跨区域数据共享,使用者数据读取的费用为 5 美元/TB,同一区域内的数据共享是免费的。有关更多信息,请参阅管理跨区域数据共享的成本控制。
- 与单区域数据共享相比,性能也会有所不同,由于网络吞吐量的原因,跨区域共享集群之间的块元数据交换和数据传输过程将花费更多时间。
元数据访问
有许多系统视图有助于获取用户有权访问的共享对象的列表。其中一些视图包括您当前连接的数据库中的所有对象,包括您在集群上有权访问的所有其他数据库中的对象,包括外部对象。视图如下:
我们建议在查询这些视图时使用非常严格的筛选条件,因为简单的 select * 会导致读取整个目录,这并不是理想的情况。例如,看看下面的查询:
此查询将尝试收集所有共享对象和本地对象的元数据,这使得元数据扫描工作量非常大,尤其是对于共享对象。
以下是可获得类似结果的更好查询:
这是适用于所有元数据视图和表的良好做法;这样可以无缝集成到多个工具中。您还可以使用 SVV_DATASHARE* 系统视图来独占地查看与共享对象相关的信息。
创建者/使用者依赖关系
在本节中,我们将讨论创建者和使用者之间的依赖关系。
使用者对创建者的影响
使用者集群上的查询不会影响创建者集群的性能或活动。所以我们可以使用数据共享实现真正的工作负载隔离。
加密的创建者和使用者
即使创建者和使用者使用不同的 AWS Key Management Service(AWS KMS)密钥进行加密,数据共享也能无缝集成。有几种复杂、高度安全的密钥交换协议可以帮助实现这一点,因此您不必担心静态加密和其他合规依赖关系。唯一要确保的是,创建者和使用者使用同构的加密配置。
数据可见性和一致性
使用者的数据共享查询不会影响创建者的事务语义。在检查事务的可见数据时,所有涉及使用者集群上共享对象的查询都遵循读取提交的事务一致性。
维护
如果在共享对象上的创建者集群上有计划好的手动 VACUUM 操作用于维护活动,则应尽可能使用 VACUUM 重新聚集。这对于大型对象尤其重要,因为它在实用程序与之交互的数据块数量方面进行了优化,与完全真空相比,这会减少数据块元数据流失。这减少了块元数据同步时间,从而使数据共享工作负载受益。
附加组件
在本节中,我们将讨论 Amazon Redshift 中用于数据共享的其他附加组件功能。
使用 Amazon Redshift 流数据进行实时数据分析
Amazon Redshift 最近发布了使用 Amazon Kinesis Data Streams 进行流式摄取摄取的预览。这样就不再需要暂存数据,并有助于实现低延迟的数据访问。通过 Amazon Redshift 集群上的流式处理生成的数据将使用实体化视图来公开。您可以通过数据共享将其作为任何其他实体化视图进行共享,并使用它在几分钟内跨集群设置低延迟共享数据访问。
Amazon Redshift 并发扩展以提高吞吐量
Amazon Redshift 数据共享查询可以利用并发扩展来提高集群的整体吞吐量。您可以在使用者集群上为预计工作负载繁重的队列启用并发扩展,以便在集群遇到繁重负载时提高整体吞吐量。
有关并发扩展的更多信息,请参阅 Amazon Redshift 中的数据共享考虑因素。
Amazon Redshift Serverless
Amazon Redshift Serverless 集群已准备好随时进行数据共享。无服务器集群也可以充当预置集群的创建者或使用者。以下是 Redshift Serverless 支持的排列:
- 无服务器(创建者)和预置(使用者)
- 无服务器(创建者)和无服务器(使用者)
- 无服务器(使用者)和预置(创建者)
结论
借助 Amazon Redshift 数据共享,您可以分散和扩展复杂的工作负载,而不必担心工作负载隔离问题。但是,与任何系统一样,随着系统规模的扩大,从长远来看,如果没有合适的优化技术,可能会带来复杂的挑战。结合这篇文章中列出的最佳实践,提供了一种主动缓解各个领域的潜在性能瓶颈的方法。
立即尝试数据共享,充分发挥 Amazon Redshift 的全部潜力,如有其他问题或需要澄清,请随时联系我们。
关于作者
 BP Yau 是 AWS 的高级产品经理。他热衷于帮助客户设计大数据解决方案,以大规模处理数据。在加入 AWS 之前,他曾帮助 Amazon.com Supply Chain Optimization Technologies 将其 Oracle 数据仓库迁移到 Amazon Redshift,并使用 AWS 技术构建了下一代大数据分析平台。
BP Yau 是 AWS 的高级产品经理。他热衷于帮助客户设计大数据解决方案,以大规模处理数据。在加入 AWS 之前,他曾帮助 Amazon.com Supply Chain Optimization Technologies 将其 Oracle 数据仓库迁移到 Amazon Redshift,并使用 AWS 技术构建了下一代大数据分析平台。
 Sai Teja Boddapati 是来自西雅图的数据库工程师。他致力于解决复杂的数据库问题,为构建最人性化的数据仓库做出贡献。业余时间,他喜欢旅行、玩游戏、看电影和纪录片。
Sai Teja Boddapati 是来自西雅图的数据库工程师。他致力于解决复杂的数据库问题,为构建最人性化的数据仓库做出贡献。业余时间,他喜欢旅行、玩游戏、看电影和纪录片。